
Getting relevant recommendations in front of your users at the right time is a crucial step for the success of your personalization strategy. However, your customer’s decision-making process shifts depending on the context at the time when they’re interacting with your recommendations. In this post, I show you how to set up and query a context-aware Amazon Personalize deployment.
Amazon Personalize allows you to easily add sophisticated personalization capabilities to your applications by using the same machine learning (ML) technology used on Amazon.com for over 20 years. No ML experience is required. Amazon Personalize supports the automatic adjustment of recommendations based on contextual information about your user, such as device type, location, time of day, or other information you provide.
The Harvard study How Context Affects Choice defines context as factors that can influence the choice outcome by altering the process by which a decision is made. As a business owner, you can identify this context by analyzing how your customers shop differently when accessing your catalog from a phone vs. a computer, or seeing the shift in your customer’s content consumption on rainy vs. sunny days.
Leveraging your user’s context allows you to provide a more personalized experience for existing users and helps decrease the cold-start phase for new or unidentified users. The cold-start phase refers to the period when your recommendation engine provides non-personalized recommendations due to the lack of historical information regarding that user.
Adding context to Amazon Personalize
You can set up and use context in Amazon Personalize in four simple steps:
- Include your user’s context in the historical user-item interactions dataset.
- Train a context aware solution with a User Personalization or Personalized Ranking recipe. A recipe refers to the algorithm your recommender is trained on using the behavioral data specified in your interactions dataset plus any user or items metadata.
- Specify the user’s context when querying for real-time recommendations using the GetRecommendations or GetPersonalizedRanking
- Include your user’s context when recording events using the event tracker.
The following diagram illustrates the architecture of these steps.
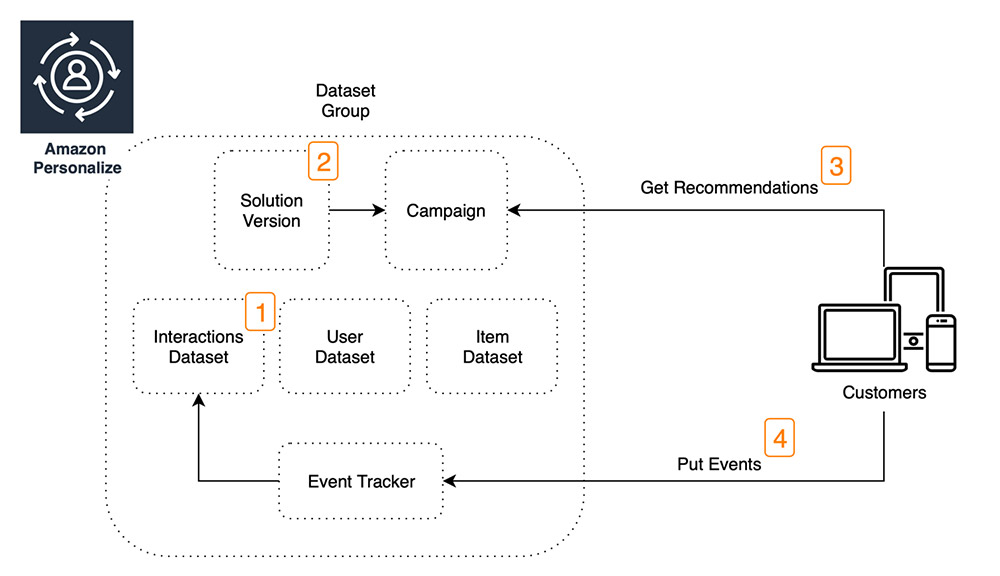
You want to be explicit about the context to consider when constructing datasets. A common example of context customers actively use is device type, such as a phone, tablet, or desktop. The study The Effect of Device Type on Buying Behavior in Ecommerce: An Exploratory Study from the University of Twente in the Netherlands has proven that device type has an influence on buying behavior and people might postpone a buying decision if they’re online with the wrong device type. Embedding device type context in your datasets allows Amazon Personalize to learn this pattern and, at inference time, recommend the most appropriate content with awareness of the user’s context.
Recommendations use case
For this use case, a travel enthusiast is our potential customer. They look at a few things when deciding which airline to travel with to their given destination. For example, is it a short or a long flight? Will the trip be booked with cash or with miles? Are they traveling alone? Where are they be departing and returning to? After they answer these initial questions, the next big decision is picking the cabin type to fly in. If our travel enthusiast is flying in a high-end cabin type, we can assume they’re looking at which airline provides the best experience possible. Now that we have a good idea on what our user is looking for, it’s shopping time!
Consider some of the variables that go into the decision-making process of this use case. We can’t control many of these factors, but we can use some to tailor our recommendations. First, identify common denominators that might affect a user’s behavior. In this case, flight duration and cabin type are good candidates to use as context, and traveler type and traveler residence are good candidates for user metadata when building our recommendation datasets. Metadata is information you know about your users and items that stays somewhat constant over a period of time, whereas context is environmental information that can shift rapidly across time, influencing your customer’s perception and behavior.
Selecting the most relevant metadata fields in your training datasets and enriching your interactions datasets with context is important for generating relevant user recommendations. In this post, we build an Amazon Personalize deployment that returns a list of airline recommendations for a customer. We add cabin type as the context and traveler residence as the metadata field and observe how recommendations shift based on context and metadata.
Prerequisites
We first need to set up the following Amazon Personalize resources. For full instructions, see Getting Started (Console) to complete the following steps:
- Create a dataset group. In this post, we name it
airlines-blog-example. - Create an
Interactionsdataset using the following schema and import data using the interactions_dataset.csv file: - Create a
Usersdataset using the following schema and import data using the users_dataset.csv file: - Create a solution. In this post, we use the default solution configurations, except for the following:
- Recipe –
aws-hrnn-metadata - Event type – RATING
- Perform HPO – True
- Recipe –
Hyperparameter optimization (HPO) is recommended if you want Amazon Personalize to run parallel trainings and experiments to identify the most performant hyperparameters. For more information, see Hyperparameters and HPO.
- Create a campaign.
You can set up the preceding resources on the Amazon Personalize console or by following the Jupyter notebook personalize_hrnn_metadata_contextual_example.ipynb example on the GitHub repo.
Exploring your Amazon Personalize resources
We have now created several Amazon Personalize resources, including a dataset group called airlines-blog-example. The dataset group contains two datasets: interactions and users, which contain the data used to train your Amazon Personalize model (also known as a solution). We also created a campaign to provide real-time recommendations.
We can now explore how the interactions and users dataset schemas help our model learn from the context and metadata embedded in the datasets.
Interactions dataset
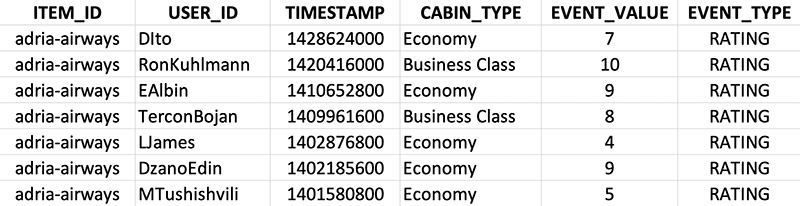
We provide Amazon Personalize an interactions dataset with a numeric rating (combination of EVENT_TYPE + EVENT_VALUE) that a user (USER_ID) has given an airline (ITEM_ID) when flying in a certain cabin type (CABIN_TYPE) at a given time (TIMESTAMP). By providing this information to Amazon Personalize in the dataset and schema, we can add CABIN_TYPE as the context when querying the recommendations for a user and recording new interactions through the event tracker. At training time, the model automatically identifies important features from this data (for our use case, the highest rated airlines across cabin types).
The following screenshot showcases a small portion of the interactions_dataset.csv file.
User dataset
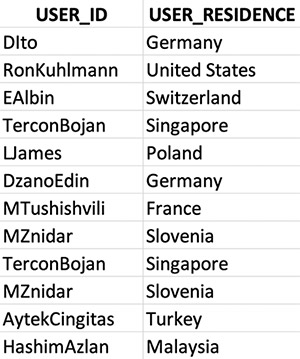
We also provide Amazon Personalize a user dataset with the users (USER_ID) who provided the ratings in the interactions dataset, assuming that they gave the rating from their country of residence (USER_RESIDENCE). In this use case, USER_RESIDENCE is the metadata we picked for these users. By providing USER_RESIDENCE as user metadata, the model can learn which airlines are interacted with the most by users across countries and regions, so when we query for recommendations, it takes USER_RESIDENCE in consideration. For example, users in Asia see different airline options compared to users in South America or Europe.
The following screenshot shows a small portion of the user_dataset.csv file.
The raw dataset of user airlines ratings from Skytrax contains 20 columns with over 40,000 records. In this post, we use a modified version of this dataset and split the most relevant columns of the raw dataset into two datasets (users and interactions). For more information about splitting the data in a Jupyter notebook, see personalize_hrnn_metadata_contextual_example.ipynb on the GitHub repo.
The next section shows how context and metadata influence the real-time recommendations provided by your Amazon Personalize campaign.
Applying context to your Amazon Personalize real-time recommendations queries
During this test, we observe the effect that context has on the recommendations provided to users. In our use case, we have an interactions dataset of numerical airline ratings from multiple users. In our schemas, the cabin type is included as a categorical value for the interactions dataset and the user residence as a metadata field in the users dataset. Our theory is that by adding the cabin type as context, the airline recommendations will shift to account for it.
- On your Amazon Personalize dataset group dashboard, choose View campaigns.
- Choose your newly created campaign.
- For User ID, enter
JDowns. - Choose Get recommendations.
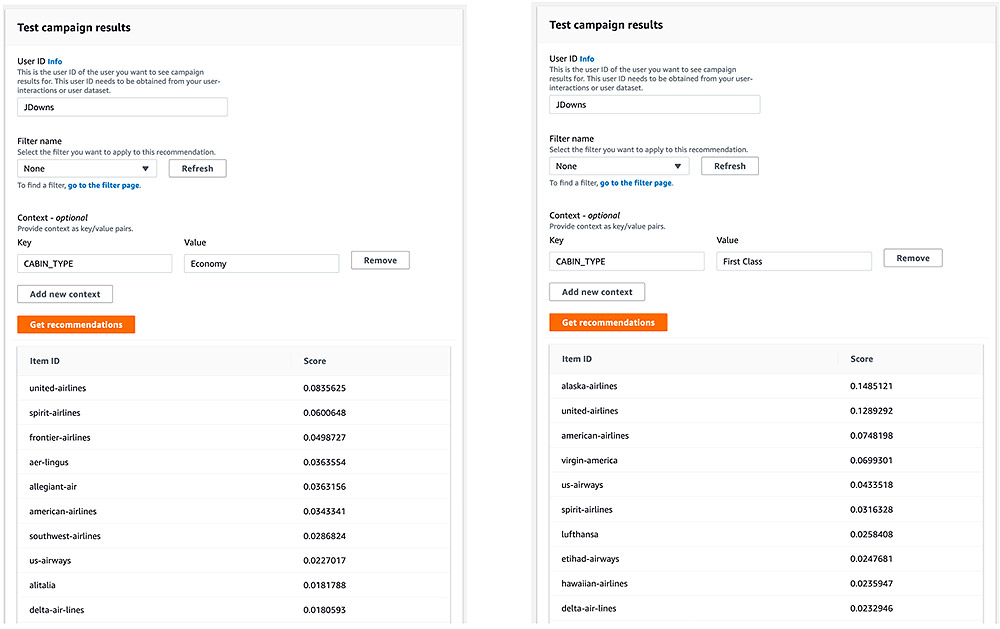
You should see a Test campaign results page similar to the following screenshot.

We initially queried a list of airlines for our user without any context. We now focus on the top 10 recommendations and verify that they shift based on the context. We can add the context via the console by providing a key and value pair. In our use case, the key is CABIN_TYPE and the value can be one of the following:
- Economy
- Premium Economy
- Business Class
- First Class
The following two screenshots show our results for querying recommendations for the same user with Economy and First Class as values for the CABIN_TYPE context. The economy context doesn’t shift the top 10 list, but the first class context does have an effect—bumping Alaska Airlines to first place on the list.
You can explore your users_dataset.csv file for additional users to test your recommendations API, and a very similar shift of recommendations based on the context you include in the API call. You can also find that the airlines list shifts based on the User Residency metadata field. For example, the following screenshots show the top 10 recommendations for our JDowns user, who has United States as the value for User Residency, compared to the PhillipHarris user, who has France as the value for User Residency.

Conclusion
As shown in this post, adding context to your recommendation strategy is a very powerful and easy-to-implement exercise when using Amazon Personalize. The benefits of enriching your recommendations with context can result in an increase in your user engagement, which eventually leads to an increase in the revenue influenced by your recommendations.
This post showed you how to create an Amazon Personalize context-aware deployment and an end-to-end test of getting real-time recommendations applying context via the Amazon Personalize console. For instructions on using a Jupyter environment to set up the Amazon Personalize infrastructure and get recommendations using the Boto3 Python SDK, see personalize_hrnn_metadata_contextual_example.ipynb on the GitHub repo.
There’s even more that you can do with Amazon Personalize. For more information about core use cases and automation examples, see the GitHub repo.
If this post helps you or inspires you to solve a problem, share your thoughts and questions in the comments.
About the Author
 Luis Lopez Soria is an AI/ML specialist solutions architect working with the AWS machine learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.
Luis Lopez Soria is an AI/ML specialist solutions architect working with the AWS machine learning team. He works with AWS customers to help them adopt machine learning on a large scale. He enjoys playing sports, traveling around the world, and exploring new foods and cultures.
from AWS Machine Learning Blog https://ift.tt/30MJyJY
via A.I .Kung Fu
No comments:
Post a Comment